.svg)
The Challenge: Finding an Inference Engine for Hybrid Architectures
When in early 2025 we started developing LFM2, our first generation of open-weight models at Liquid AI, we faced a critical challenge: existing inference engines couldn't handle the diverse architectures we needed to profile during neural architecture search. Our goal was to create the first generation of ultra efficient Language Models that could run on-device.
To find LFM2, we had to evaluate a large quantity of different models, layers, and operations, including various forms of attention, convolutional layers, and multiple types of recurrences, many of which required hybrid caching for realistic token generation profiling.
We initially explored several popular inference engines, but quickly hit a roadblock. Most engines were optimized for standard transformer models and lacked support for the hybrid cache mechanism that our architecture demanded.
Without the right inference engine, we risked either compromising our innovative architecture or limiting deployment to cloud-only scenarios. We needed a solution that could handle our hybrid model structure while delivering the performance and efficiency that on-device AI applications require.
The Solution: ExecuTorch's Enterprise-Grade Automation
After evaluating our options, we chose PyTorch ExecuTorch, and the decision paid off very quickly.
ExecuTorch's hybrid cache support was the obvious draw, enabling our LFM2 unique architecture to run efficiently from the start. But what really set ExecuTorch apart was its automated, enterprise-grade approach to model deployment. With a single command-line instruction, we could convert an exportable graph into a self-contained bundle that included weights, metadata, and the execution graph: everything needed to run the model, packaged together.
This streamlined workflow stood in sharp contrast to other inference engines that decouple implementation and model information, requiring developers to manage compatible runtimes for each component separately. For us, this meant faster iteration cycles and less time wrestling with deployment complexity.
The integration wasn't entirely seamless. Some custom operations in LFM2 required approximately 2-3 weeks of graph reworking to make the model exportable. But once that initial engineering investment was made, ExecuTorch's automated approach began to shine. By July 2025, LFM2 was successfully running on-device and released to the world.
Perhaps most valuable was the support from ExecuTorch's maintainers, who proved very helpful in solving early-stage problems. Their collaborative approach helped us navigate the inevitable challenges of adopting new infrastructure for novel model architectures.
In the next section, we share inference benchmarks for LFM2 running on ExecuTorch.
The Results: Measurable Performance Gains Across Devices
We tested our ExecuTorch-powered models across two hardware platforms: AMD Ryzen AI 9 HX 370 and Samsung S24. Across different LFM2 model sizes, from 350M to 4B parameters, we saw consistent performance advantages:
- Lower latency in both prefill and decode phases, enabling real-time applications
- Reduced memory footprint, enabling deployment on memory-constrained devices
- Smaller model file sizes for faster download and installation
Throughput comparison on CPU in ExecuTorch
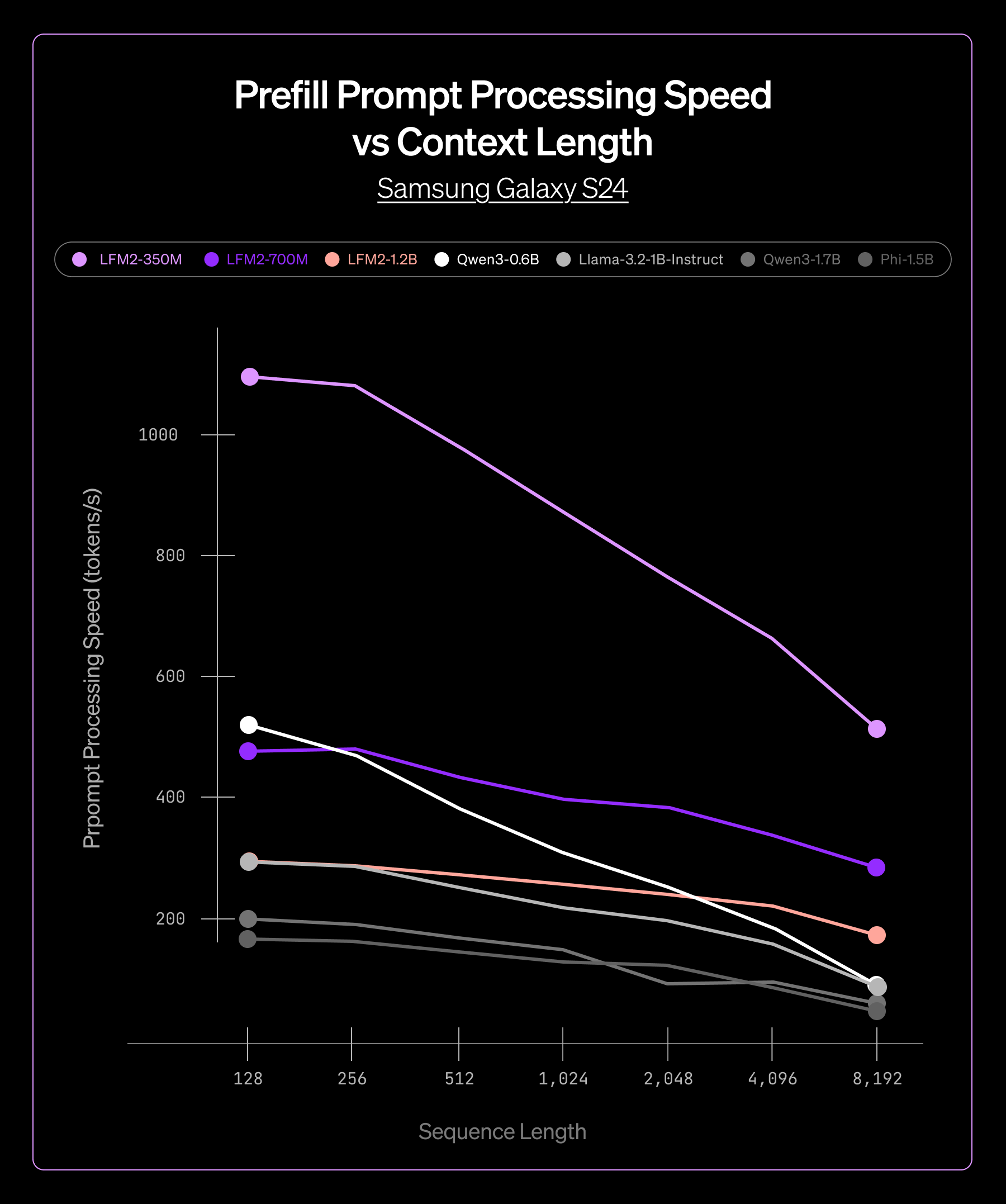
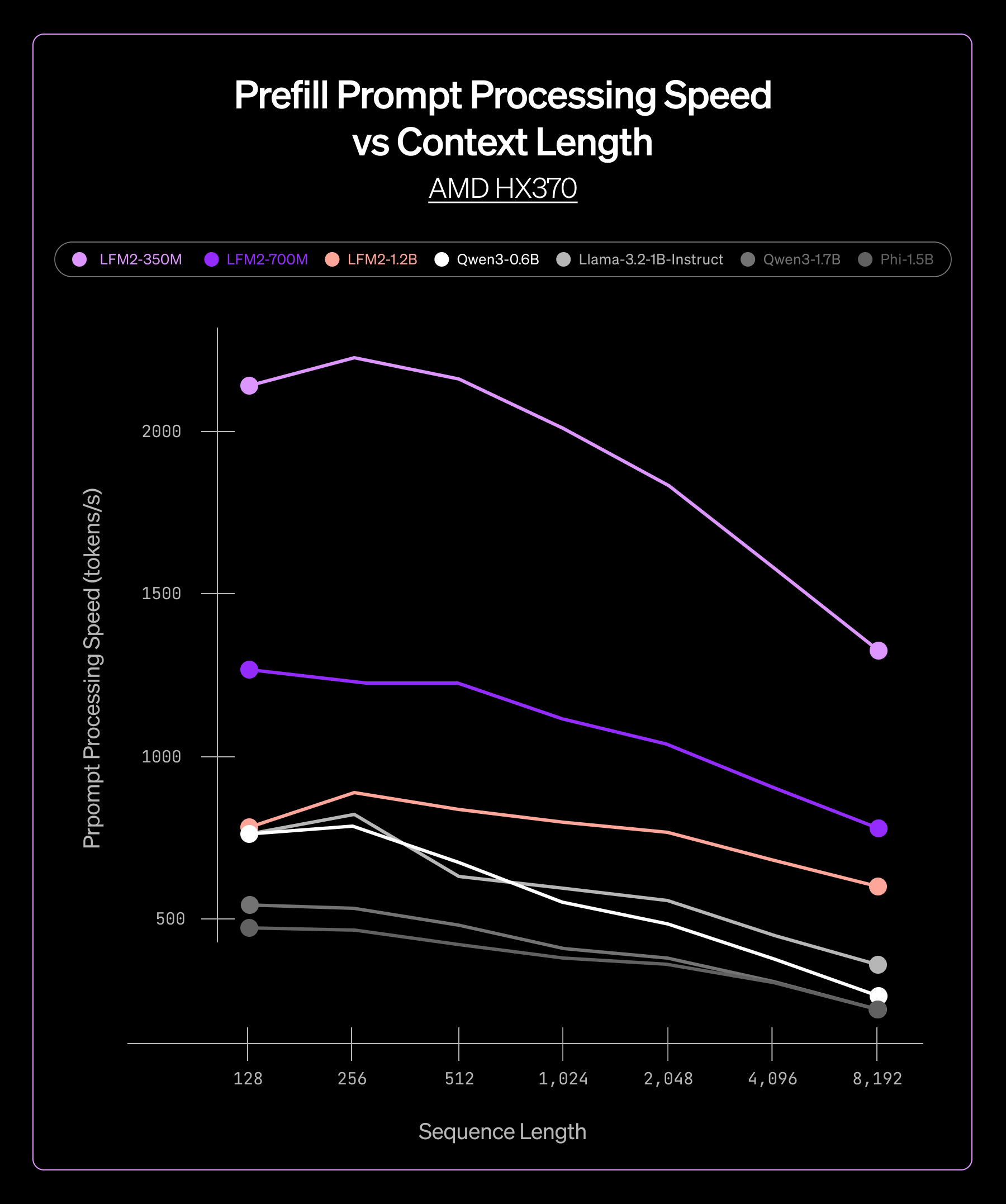

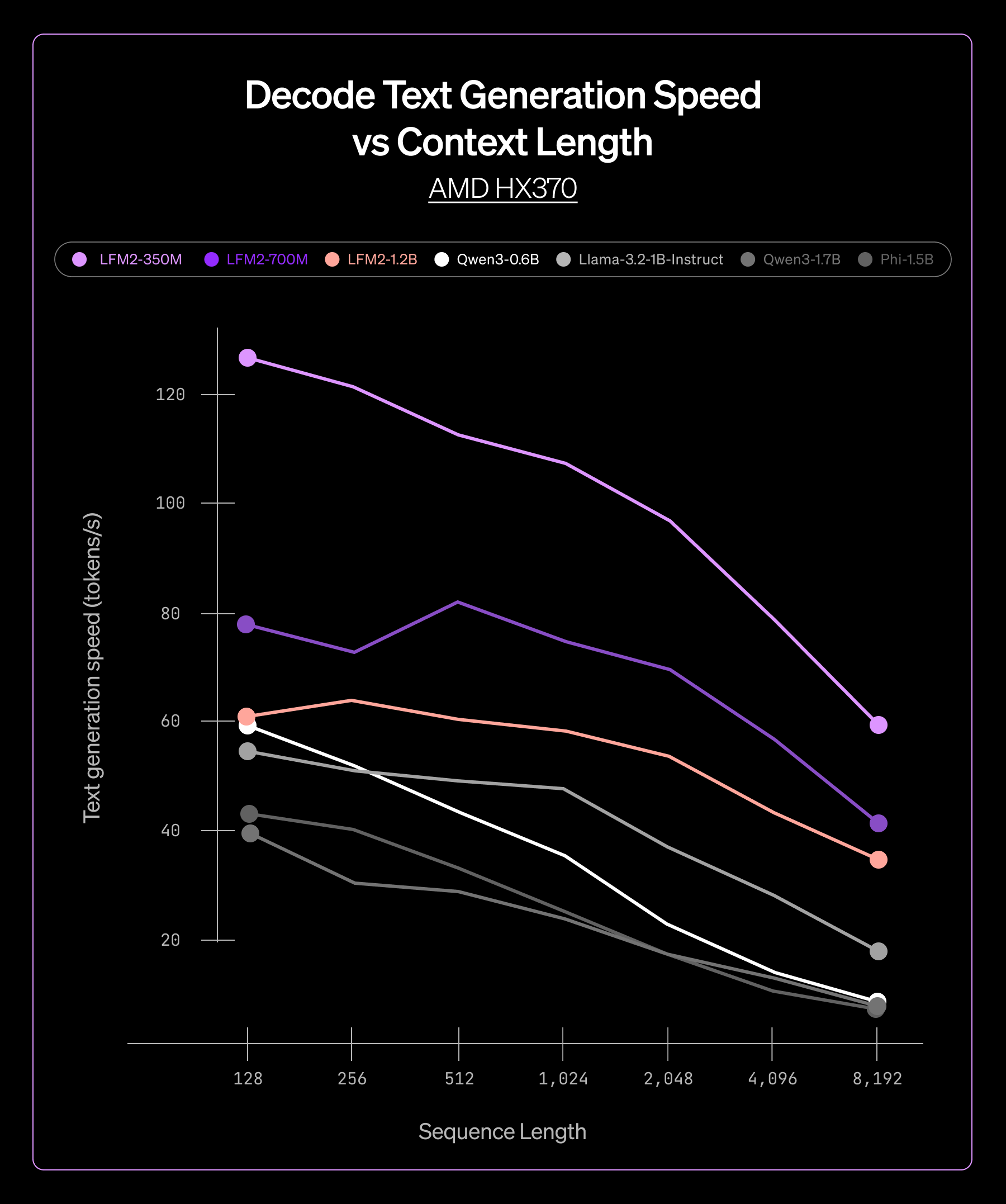
This consistency meant we could confidently deploy across our product line, knowing that ExecuTorch would deliver reliable performance regardless of model size or target hardware.
